Test Design Techniques for Effective Software Testing
Table of Contents
Intro
Software testing is crucial for building high-quality, bug-free software applications. However, effectively testing a complex application requires more than just randomly clicking around and hoping to catch errors. By leveraging test design techniques, you can develop focused test plans. This allows you to efficiently validate expected behavior and uncover edge-case defects.
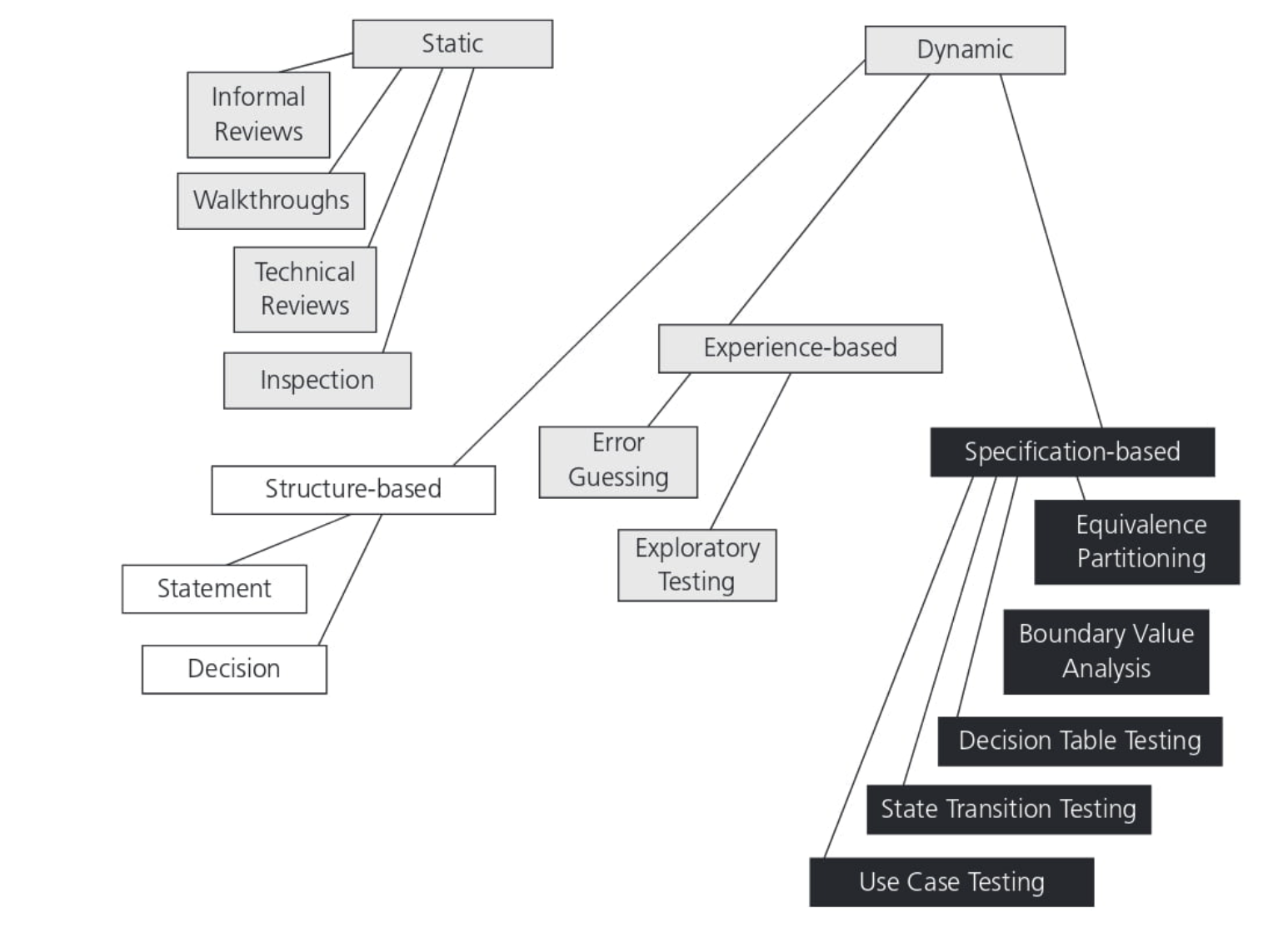
In this chapter we look at dynamic test techniques, which are subdivided into
three more categories: black-box (also known as specification-based, behavioural or behaviour-based techniques), white-box (structure-based or structural tech- niques) and experience-based. Black-box test techniques include both functional and non-functional techniques (that is, testing of quality characteristics). The techniques covered in the Syllabus are summarized in Figure 1.
Equivalence Partitioning
Equivalence partitioning splits a program’s input data domains into categories of equivalent classes. Each partition consists of valid or invalid classes with similar characteristics. You then selectively pick representative test case input values from each partition class.
For example, with numeric input ranges you might design partitions for normal range values, minimum/maximum values, out-of-range data, and invalid formats like text instead of numbers. By testing one value from each section, you efficiently cover a wider range of parameter types with fewer test cases.
A Deep Dive on Equivalence Partitioning
Equivalence partitioning is a fundamental test design method to effectively cover input data domains. By dividing inputs into equivalent classes that meet similar quality criteria, you optimize the number of test cases needed achieve adequate coverage.
Defining Equivalence Partitions
To leverage equivalence partitioning:
- Analyze the input data domains and outputs for the function under test.
- Divide domains into equivalence partitions:
- Valid partitions - Divisions of valid inputs
- Invalid partitions - Inputs you specifically want to exclude
- Define test case selection criteria for each partition:
- Valid partitions - Choose inputs that should yield correct functioning
- Invalid partitions - Choose inputs that should be rejected or handled properly
- Select test data per partition rules to cover all equivalence classes.
Equivalence partitioning test cases should satisfy four key objectives:
- Trigger intended functionality
- Expose improper handling of invalid values
- Detect defects on partition edges
- Identify gaps in requirements
Example Partitions
As an example, consider testing input validation for a field that accepts alphanumeric ZIP codes of length 5 or 9.
Valid partitions might divide into numeric-only ZIPs versus alphanumeric ZIPs. Invalid data partitions might cover other lengths or special characters.
Test cases derived per partition rules would include:
Valid Partitions
- 75201 (numeric, 5 chars)
- AA123 (alphanumeric, 5 chars)
- 987654321 (numeric, 9 chars)
Invalid Partitions
- TEXT (rejects non-alpha chars)
- 12345 (rejects wrong length)
- 98765-4321 (rejects non-alphanumeric chars)
By effectively applying equivalence class partitioning, 4 test cases here can cover a huge set of potential ZIP code input variants. This simplifies test design to offer good coverage without excessive redundant test cases.
Boundary Value Analysis
While equivalence partitioning offers high-level test coverage for broad input domains, additional test cases are needed to cover interesting “corner case” values at partition edges. Boundary value analysis helps derive additional test cases for equivalence partition boundaries.
Consider testing the valid age range of 13 to 120 for setting up user accounts. Using boundary value analysis you would design test cases for partition edges like minimum age, maximum age, below minimum, above maximum, as well as perhaps an edge inside each partition like 14, 119.
Example Scenario: User Age Verification in an Application
Suppose you have an application that requires the user's age to be between 18 and 60 years inclusive. The boundaries in this case are 18 and 60.
Boundary Values for Testing:
- Minimum Boundary Value: 18
- Just Below Minimum: 17 (Invalid)
- Just Above Minimum: 19 (Valid)
- Maximum Boundary Value: 60
- Just Below Maximum: 59 (Valid)
- Just Above Maximum: 61 (Invalid)
Test Cases:
- Test Case 1: Enter age as 17. Expect the application to reject the input or display an error message (since it's below the minimum valid age).
- Test Case 2: Enter age as 18. Expect the application to accept the input (as it's the minimum valid age).
- Test Case 3: Enter age as 19. Expect the application to accept the input (valid age just above the minimum).
- Test Case 4: Enter age as 59. Expect the application to accept the input (valid age just below the maximum).
- Test Case 5: Enter age as 60. Expect the application to accept the input (as it's the maximum valid age).
- Test Case 6: Enter age as 61. Expect the application to reject the input or display an error message (since it's above the maximum valid age).
By testing these boundary values, you can more effectively find edge case bugs that might be missed with random testing. This approach is efficient because it targets the points where software behavior is most likely to fail. Boundary value analysis can be applied to various types of input data, such as numbers, dates, or even string lengths, and is a crucial part of a comprehensive testing strategy.
Combining EP and BVA
By combining both techniques, you cover a comprehensive range of input values:
- Equivalence Partitioning ensures testing with representative values from each partition.
- Boundary Value Analysis focuses on edge cases, where errors are most likely to occur.
This combined approach is effective in identifying defects that might occur in different input ranges, improving the overall quality of the software.

Decision Table Testing
For complex logic flows based on multiple decision conditions, decision table testing offers a robust method to generate effective test cases. Each logical condition and resultant decision rule is mapped out in a table consisting of individual boolean logic test parameters.
By testing true and false combinations for each parameter, overall test coverage is increased by ensuring each section of underlying business logic is validated. This also simplifies analysis of complex combinatorial logic conditions.
A Closer Look at Decision Table Testing
Complex application logic often combines multiple interdependent conditions and rules. One change can break functionality in subtle ways that are hard to detect. Decision table testing provides a robust way to test these multilayered logic flows.
How Decision Tables Work
Decision tables allow you to break down complex conditional logic into simple boolean logic parameters. These parameters and their possible states are mapped into a table. Truth tables are then derived to generate test cases that validate both single and combination outcomes.
For example, consider an e-commerce site that applies the following complex rules to determine shipping eligibility:
- Orders under $50 have a $5 small order fee
- Free shipping is available for orders over $100
- Free shipping option excludes hazardous materials
- Some rural zip code areas have liftgate fees
This can be modeled with a decision table:
| Order Total | Hazardous Item | Rural Zip | Expected Outcome |
|---|---|---|---|
| <$50 | No | No | Collect small order fee |
| >=$100 | No | No | Free standard shipping |
| >=$100 | Yes | No | No free shipping |
| <$100 | No | Yes | Collect liftgate fee |
We can expand this table to cover other test parameters like:
- Edge case values: $49.99, $100.00, etc.
- Valid and invalid rural zip codes
- Multiple items including hazardous
- International addresses
From this table we derive test cases that combine true and false for each parameter. This serves to validate both individual logic constraints and their combinations.
Benefits of Decision Table Testing
- Methodically test complex conditional flows
- Map all combinations of interdependencies
- Reveal logic gaps or incorrect rule precedence
- Simplify analysis of multilayered logic branches
- Improve coverage while minimizing test cases
By leveraging decision table testing you can improve quality and defect detection for complex business logic. This method serves as an important technique in a comprehensive test design strategy.
Decision table exercise from ISTQB
Scenario: If you hold an over 60s rail card, you get a 34% discount on whatever ticket you buy. fI you are travelling with a child (under 16), you can get a 50% discount on any ticket fi you hold a family rail card, otherwise you get a 10% discount. You can only hold one type of rail card.
Task: Produce a decision table showing all the combinations of fare types and resulting discounts and derive test cases from the decision table.
Use Case Testing
Use cases define realistic end-user scenarios for interacting with an application. Aligning test cases to match use case steps offers multiple benefits compared to simply testing arbitrary functions.
First it focuses testing on critical workflows from an end-user perspective vs just covering code paths. Second it provides insight to gaps in requirements and can clarify vague use cases by testing real world scenarios. Expanding test coverage by use case helps improve overall quality of user experience.
Error Guessing
While the techniques discussed so far apply structured test design methods, an experienced quality assurance team should supplement with intuitive error guessing techniques. This leverages knowledge of common pitfalls and past defects to guess errors that may occur.
Some typical categories of errors to guess might include:
- Extreme input conditions - Will extremely small, large, or negative numbers break logic constraints?
- Resource limits - What happens when memory, storage, bandwidth is full?
- Invalid inputs - How does logic handle incorrect or unexpected data types?
- Unauthorized access - Can restricted views be accessed?
- Random chaotic sequences - Do repeated or random inputs expose concurrent processing issues?
- Interrupted states - What if a process is forced stopped mid-execution?
Error guessing adds immense value on top of structured test plans by leveraging domain experience of past issues that tend to recur. It encourages considering potential failure modes beyond happy path scenarios. Testing is as much an art as it is a science, and guessing likely errors is a technique that should be encouraged. Even when guesses don't find new defects, they may reveal opportunities to add robustness against potential future problems.
State Transition Testing
Applications often behave differently depending on the current state they are in. Testing different transitions between these states is important to validate correct behavior.
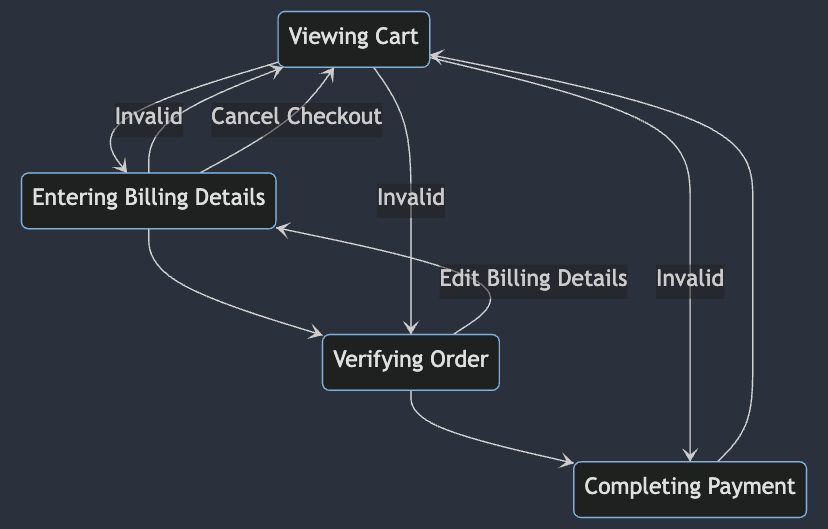
For example, consider an e-commerce checkout process consisting of the following logical states:
- Viewing cart
- Entering billing details
- Verifying order
- Completing payment
Valid transitions between these states would be:
1 -> 2 -> 3 -> 4 4 -> 1 (After completion, start over)
Some invalid transitions to test might include:
1 -> 3 (Skip billing details) 2 -> 1 -> 4 (Go backwards and skip steps)
More complex state models may have additional transition paths like:
3 -> 2 (Edit billing details after validation) 2 -> 1 (Cancel checkout and return to cart)
To test these flows:
- Create state transition diagrams modeling the valid user paths
- Specify boundary and error states transitions should avoid
- Design test cases to force both normal and disrupted transitions
For example:
- Enter invalid payment after state 3 to force backwards transition
- Crash the app between states 2 and 3 to validate persistence on restart
- Seed bad data between transitions to validate data integrity checks
Testing various state transitions helps reveal bugs from improper state management, especially for complex asynchronous flows across backend services. Maintaining disciplined state models and testing possible sequences is important for building resilient system behavior.
Applying Test Design Techniques
Leveraging different test design techniques allows you to develop optimized test suites tailored to validate a system. Combining these methods with both white box and black testing ensures thorough test coverage at unit, integration and system levels. Focusing too much on either manual or only automated testing leaves gaps in catching defects. The best approach is to apply robust test design early, enable tests to be automated, and supplement with exploratory testing where gaps exist or defects are likely found.